This blog is meant to be about things I’ve learned, whether through courses/training/talks or through my own mistakes.
I realised that I haven’t really spoken about my recent journey from story points/velocity to the liberating world of throughput, Monte Carlo, and data-based probability forecasting. Liberating because instead of endless time spent “sizing” and arguing about what to size or how to size it, now all I need to help my team get feedback (and help my Product Owner give forecasts) is to pull data about what has actually happened. Most of the time, the team doesn’t even need to be involved: they can merrily continue doing value-add activities.
The one downside is, people don’t always like the answers the numbers give them.
Before I continue, I’d like to add a disclaimer. Statistics hurt my brain. I rely heavily on tools and techniques advocated by people a lot smarter than me. If you’re in any way interested in learning more about the topics I’m about to mention, please look up people like Dan Vacanti, Prateek Singh and Troy Magennis. I’ll add some links at the end of this to sites and blogs that have helped my teams and me get to grips with the basics, but I am not qualified to explain how this works. I understand why it works, I just can’t explain/teach it.
First, some background. I have always found story points and velocity extremely painful to work with when it comes to forecasting. Planning Poker can be a good tool to help a team have a conversation and check in that people are on the same page regarding how big something is, but once we know no one is sitting on a piece of hidden information or an assumption that no one else in the room is aware of, to use them for anything more becomes super complicated and “fragile”. And I’m not even talking from a statistical perspective (ref. Flaw of Averages.). If you’re using velocity for forecasting, there are plenty of sizing antipatterns out there, WHICH MOST PEOPLE DO ALL THE TIME, that break it. I’m not going to go into these now. I’ve spent years trying to explain/teach about sizing antipatterns. One of the greatest reliefs about abandoning velocity as a planning tool is that I no longer have to worry about it! If teams find sizes helpful (especially when transitioning), then they can do it when and how they want to, but I no longer use velocity for forecasting so it truly doesn’t matter what their number is at the end of the day – or even if they capture it anywhere.
So what is this magic and how does it work?
The first bit of magic is throughput. How many items your team completes in a period. (If you’re doing Scrum, your period is likely to be a sprint, but the period can be however long or short you want or need it to be, as long as you always use the same period across your calculations i.e. don’t use throughput based on sprints (weeks) to try to forecast based on days.) Now, you do need to agree and understand what done means. For some of my teams, done is ready for Production but not yet deployed. For others, it might be deployed to Production. It will depend on how your teams work and what is in their control. Again, what done is for you doesn’t really matter in this context, as long as it’s always clear what done means in your world. So the first piece of data you need, is 3-10 datasets, over a period similar to the one you want to forecast, which gives you how many things the team finished in each period. If you’re using a tracking tool, this shouldn’t be hard to get.
The second bit of magic is Monte Carlo. I am not qualified to explain Monte Carlo or how it works. Luckily someone else has done a really good job of doing it for me in this Step-by-step Guide to Monte Carlo Simulations. Monte Carlo answers two very common questions:
- How many things are you likely to complete in this amount of time? And,
- How long are you likely to take to complete this many things?
And the best thing? Probability is built in! So you can say we have a 50/50 chance of completing this in 3 months or less but an 85% chance of completing this in 7 months or less. And what inputs does this wonderful magic need? Just your throughout. That is all. No estimating or sizing. No sitting in rooms trying to break things down. No arguing over capacity and approaches and such like. Just counts of things completed in periods.
So I can hear some people already have questions like “But things don’t take the same amount of time” and “What if it’s a really big thing – surely you need to know how many smaller things there are?”. The first concept that makes this easier is “right-sizing”. It’s always a good thing to break things down as small as possible (without losing value). So teams should still do this. And for your team, especially if you’re doing Scrum, you probably already have a “right size” in mind. Perhaps things shouldn’t take longer than two weeks to be done? Or perhaps a week? Whatever it is, agree what a “right size” is in your space to get something to your definition of done, and as long as most of the time things are about that size (or smaller) the outliers will work themselves out in the wash (you’ll have to either trust me on this or go learn more about “The Law of Large Numbers”). Related to right-sizing, there is also a very powerful feedback tool called “Aging”, but that will need to be a topic for another blog post.

The second question could be more complicated. If you have something really big you probably would break it down to do the work. The simplest way would probably be to go and look at work that you think was a similar size and count how many pieces that was in the end. Or if you want to use Monte Carlo to help you, here is an idea for how one could do it (although now it starts to feel like you’re in the “Inception” movie).
At the end of the day, you don’t have to trust me at all. If you’re curious, then I’d encourage you to run an experiment and use Monte Carlo forecasting in parallel with whatever technique you’re currently applying and compare the results. I’d be interested to hear what you uncover!
LINKS
- How many bottles of whisky will I drink in 4 months?
- Step-by-step guide to Monte Carlo simulations
- Framework Agnostic Capacity Planning
- Monte Carlo case study
- Book: “When will it be done?”
- Spreadsheets and Tools
- An idea for how to do feature planning: Using Probabilistic Forecasts for Feature Planning















 My team were struggling to make their sprint commitments. Sprint after sprint, we’d go into planning, pick the stories that we believed we could finish in the sprint, and get to the end with things not where we wanted them to be. To make matters worse, stories were piling up towards the end of the sprint, leaving testing (and feedback) right to the end. Our best intentions were just not translating into a workable plan and it was hard to see why. And then someone suggested that we try visualise our plan in Sprint Planning 2 (SP02): would it help if we created a Gantt?
My team were struggling to make their sprint commitments. Sprint after sprint, we’d go into planning, pick the stories that we believed we could finish in the sprint, and get to the end with things not where we wanted them to be. To make matters worse, stories were piling up towards the end of the sprint, leaving testing (and feedback) right to the end. Our best intentions were just not translating into a workable plan and it was hard to see why. And then someone suggested that we try visualise our plan in Sprint Planning 2 (SP02): would it help if we created a Gantt?
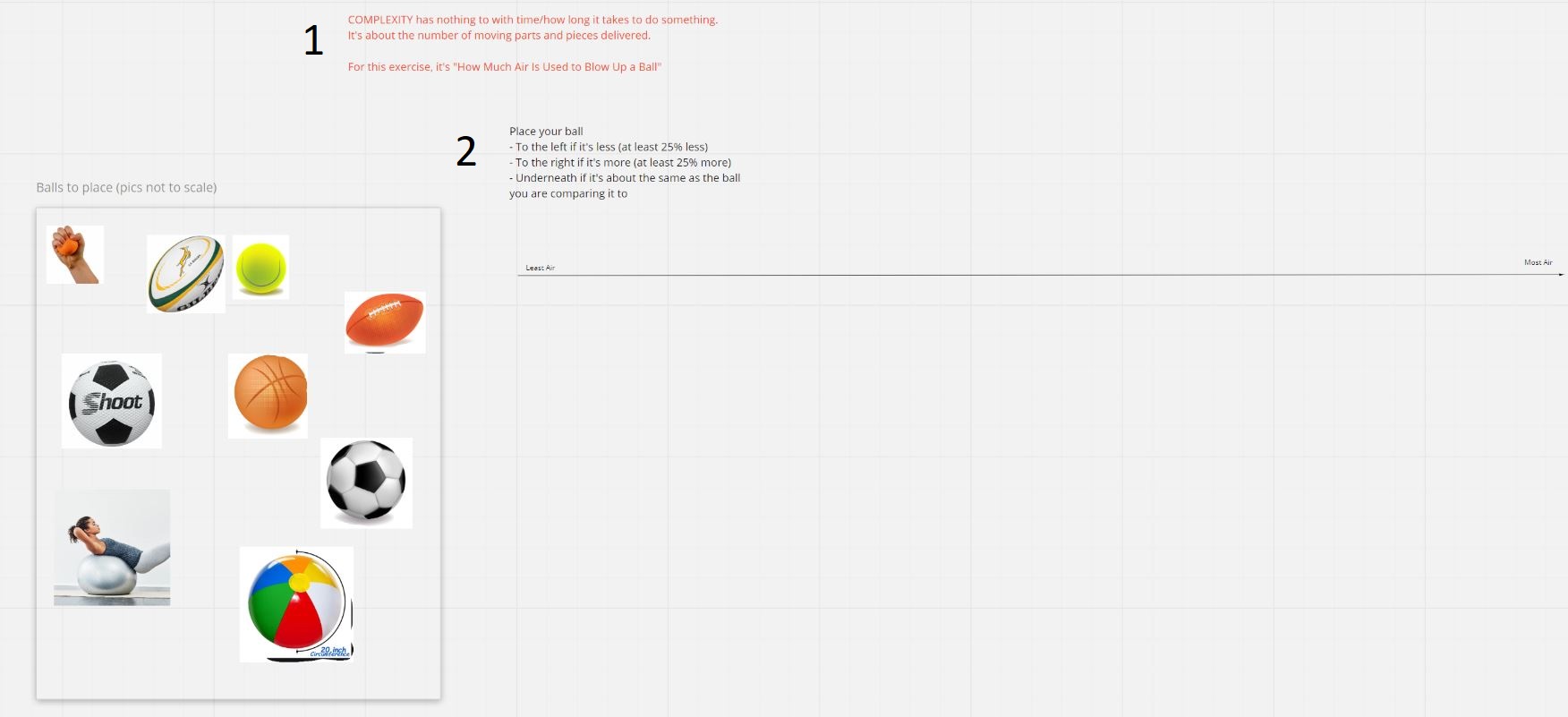


 Round 2: Buckets
Round 2: Buckets